Linux驱动-内联汇编与ARM架构简述
2024年7月 · 预计阅读时间: 5 分钟
内联汇编#
有时使用 c 语言实现一个简单的操作,对应的汇编函数可能会很复杂,因此使用内联汇编,可以在 c 语言程序中使用汇编代码。
有些特殊的算法需要我们手工优化,这时就需要手写汇编代码;或是有时需要调用特殊的汇编指令(比如使用 ldrex/strex 实现互斥访问),这都涉及内联汇编。
直接使用汇编实现加法:
根据 ATPCS 规则,main 函数调用 add(a, b)时,会把第一个参数存入 r0 寄存器,把第二个参数存入 r1 寄存器。在上面第 6 行里,把 r0、r1 累加后,结果存入 r0:根据 ATPCS 规则,r0 用来保存返回值。
使用内联汇编

asm也可以写作“asm”,表示这是一段内联汇编。
asm-qualifiers有 3 个取值:volatile、inline、goto。
volatile 的意思是易变的、不稳定的,用来告诉编译器不要随便优化这段代码,否则可能出问题。其他 2 个取值我们不关心,也比较难以理解,不讲。
AssemblerTemplate汇编指令,用双引号包含起来,每条指令用“\n”分开.
eg:
OutputOperands输出操作数,内联汇编执行时,输出的结果保存在哪里。
格式如下,当有多个变量时,用逗号隔开:
asmSymbolicName是符号名,随便取,也可以不写。constraint表示约束,有如下常用取值:constraint 描述 m memory operand,表示要传入有效的地址,只要 CPU 能支持该地址,就可以传入 r register operand,寄存器操作数,使用寄存器来保存这些操作数 i immediate integer operand,表示可以传入一个立即数 constraint前还可以加上一些修饰字符,比如“=r”、“+r”、“=&r”,含义如下:constraint Modifier Characters 描述 = 表示内联汇编会修改这个操作数,即:写 + 这个操作数既被读,也被写 & 它是一个 earlyclobber (早修改)操作数,防止它在后面的指令中被覆盖。
这就是告诉编译器:给我分配一个单独的寄存器,别为了省事跟输入操作数用同一个寄存器。cvariablename是 C 语言的变量名。示例 1
它的意思是汇编代码中会通过某个寄存器把结果写入 sum 变量。在汇编代码中可以使用“%[result]”来引用它。
示例 2
在汇编代码中可以使用“%0”、“%1”等来引用它
InputOperands参数和上面的
OutputOperands一样示例
它的意思变量 a、b 的值会放入某些寄存器。在汇编代码中可以使用%[a_val]、%[b_val]使用它们。
Clobbers在汇编代码中,对于“OutputOperands”所涉及的寄存器、内存,肯定是做了修改。但是汇编代码中,也许要修改的寄存器、内存会更多。比如在计算过程中可能要用到 r3 保存临时结果,我们必须在“Clobbers”中声明 r3 会被修改。
Clobbers 描述 cc 表示汇编代码会修改“flags register” memory 表示汇编代码中,除了“InputOperands”和“OutputOperands”中指定的之外,还会会读、写更多的内存 示例
ARM 架构#
参看:韦东山《裸机开发文档》第 5 章 - ARM 架构 、 汇编。
ARM 芯片属于精简指令集计算机(RISC:Reduced Instruction Set Computing)
(1)ARM 架构的简单介绍#
IMX6UL 使用 Cortex-A7 架构,Cortex-A7 架构的运行模式有 9 种,分别为 User、Sys(System)、FIQ、IRQ、ABT(Abort)、SVC(Supervisor)、UND(Undef)、MON(Monitor)、Hyp 模式。
除了 User 模式属于非特权模式,其它 8 种处理器模式都是特权模式.
- 运行模式可以通过软件进行任意切换,也可以通过中断或者异常来进行切换。
- 大多数的程序都运行在用户模式,用户模式下是不能访问系统所有资源的,有些资源是受限的,要想访问这些受限的资源就必须进行模式切换。
- 用户模式是不能直接进行切换的,用户模式下需要借助异常来完成模式切换,当要切换模式的时候,应用程序可以产生异常,在异常的处理过程中完成处理器模式切换。(比如,在 Linux 应用开发中使用系统调用,就是发起一个系统调用中断进入内核态,然后使用内核态下的相关系统调用处理例程)
在某种模式下,CPU 执行时使用的是这种模式的资源,这样就可以免去切换时保存上一个模式所使用的寄存器。
(2)ARMv7 架构 Cotex-A7 寄存器#
Cortex-A7 有 9 种运行模式,每一种运行模式都有一组与之对应的寄存器组,如下图:
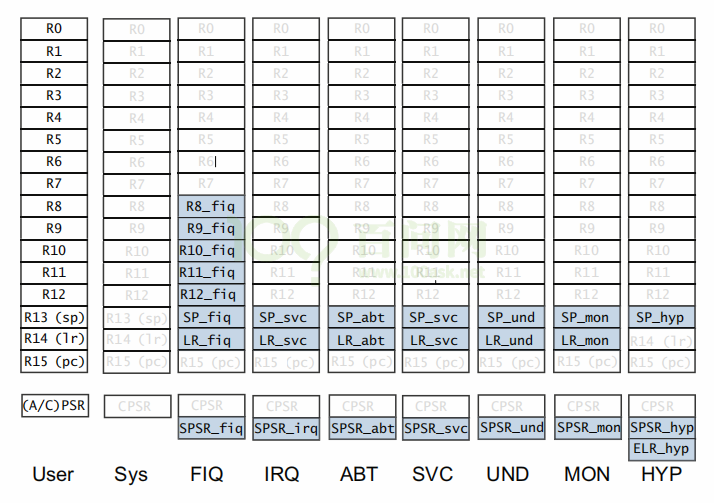
- 浅色字体是与 User 模式所共有的寄存器
- 浅蓝色背景是各个模式所独有的寄存器,即在所有的模式中,低寄存器组(R0~R7)是共享同一组物理寄存器的,只是一些高寄存器组在不同的模式有自己独有的寄存器,比如 FIQ 模式下 R8~R14 是独立的物理寄存器。
- 9 种运行模式的寄存器合计有 34 个
通用寄存器#
在 ARMv7 结构中通用寄存器有 R0-R12,共 13 个32 位通用寄存器;
在 ARMv8 结构中通用寄存器有 R0-R30,共 31 个64 位通用寄存器,其中包括了栈帧寄存器(FP)和链接寄存器 LR。
未备份寄存器#
R0~R7,因为在所有的运行模式下 R0~R7 寄存器都是相同的。
备份寄存器 R8-R12 SP LR#
R8~R12 寄存器有两种物理寄存器,在快速中断模式下(FIQ)它们对应着 Rx_irq(x=8~12)物理寄存器,其他模式下对应着 Rx(8~12)物理寄存器。
R13(SP) ,栈指针,有 8 个物理寄存器,其中一个是 User 和 Sys 模式共用的,剩下的 7 个分别对应 7 种不同的模式。
- FP:栈顶指针,指向一个栈帧的顶部,当函数发生跳转时,会记录当时的栈的起始位置。
- SP:栈指针(也称为栈底指针),指向栈当前的位置
关于 gcc 就有一个关于 stack frame 的优化选项,加上该选项则忽略掉 FP 栈顶指针,(高版本默认是不加 FP 的)
R14(LR) ,链接寄存器,有 7 个物理寄存器,其中一个是 User、Sys 和 Hyp 模式所共有的,剩下的 6 个分别对应 6 种不同的模式
使用 R14(LR)来存放当前子程序的返回地址,如果使用 BL 或者 BLX 来调用子函数的话,R14(LR)被设置成该子函数的返回地址,在子函数中,将 R14(LR)中的值赋给 R15(PC)即可完成子函数返回,如
mov pc,lr
程序计数器 R15(PC)#
保存着当前执行指令地址值加 8
因为 ARM 处理器是三级流水线:取指->译码->执行,循环执行。比如当前正在执行第一条指令的同时也对第二条指令进行译码,第三条指令也同时被取出存放在 R15(PC)中,即 R15(PC)总是指向当前正在执行指令地址再加上 2 条指令的地址。
对于 32 位的 ARM 处理器,每条指令是 4 个字节,所以 R15(PC) = 当前执行指令地址 + 8 个字节
程序状态寄存器 PSR#
- 分为当前程序状态寄存器 CPSR 与备份程序状态寄存器 SPSR。
- 负数/正数、比较的两个数大小相等、进位、控制指令执行状态、大小端控制位等
(3)汇编#
CISC 复杂指令集计算机,Complex Instruction Set Computer,比如 x86
RISC 精简指令集计算机,Reduced Instruction Set Computing,比如 ARM,RISC-V
ARM 芯片属于精简指令集计算机(RISC:Reduced Instruction Set Computing),它所用的指令比较简单,有如下特点:
- 对内存只有读、写指令
- 对于数据的运算是在 CPU 内部实现
- 使用 RISC 指令的 CPU 复杂度小一点,易于设计
常用的汇编指令一般有 mov、bl/b、add/sub、ldm/stm、push/pop 等等。
mov:用于将一个寄存器的值或立即数移动到另一个寄存器,
- 示例:
MOV R0, #5将立即数5移动到寄存器R0中。- 示例:
MOV R1, R2将寄存器R2的值移动到寄存器R1中。
bl: Branch with link,跳转并把返回地址记录在 LR 寄存器里
b: Branch,跳转指令。相比于 BL 指令,它并不保存下一条指令的地址到 LR 寄存器。
add:执行加法操作,将两个操作数相加,并将结果存储在目标寄存器中。如ADD RO, R1, R2
LDR(Load Register):从内存中加载数据到寄存器。
- 示例:
LDR R0, [R1]从寄存器R1指向的内存地址中加载数据到寄存器R0中。
STR(Store Register):将寄存器中的数据存储到内存中。
- 示例:
STR R0, [R1]将寄存器R0中的值存储到寄存器R1指向的内存地址中。
LDM和STM:批量加载和存储寄存器数据的指令
条件码:
(1)IA:(Increase After) 每次传送后地址加 4,其中的寄存器从左到右执行,例如:STMIA R0,{R1,LR} 先存 R1,再存 LR
(2)IB:(Increase Before)每次传送前地址加 4,同上
(3)DA:(Decrease After)每次传送后地址减 4,其中的寄存器从右到左执行,例如:STMDA R0,{R1,LR} 先存 LR,再存 R1
(4)DB:(Decrease Before)每次传送前地址减 4,同上
(5)FD: 满递减堆栈 (每次传送前地址减 4)
(6)FA: 满递增堆栈 (每次传送后地址减 4)
(7)ED: 空递减堆栈 (每次传送前地址加 4)
(8)EA: 空递增堆栈 (每次传送后地址加 4)
PUSH和POP:在 ARMv7 中,这些指令用于将寄存器的内容压入栈或从栈中弹出内容。
- 示例:
PUSH {R0, R1}将寄存器R0和R1的值压入栈。- 示例:
POP {R0, R1}从栈中弹出两个值到寄存器R0和R1中。
(4)ATPCS 规则#
ARM-THUMB procedure call standard(ARM-Thumb 过程调用标准)的简称,基于 ARM 指令集和 THUMB 指令集过程调用的规范,规定了调用函数如何传递参数,被调用函数如何获取参数,以何种方式传递函数返回值。
- 在函数中,通过寄存器 R0~R3 来传递参数,被调用的函数在返回前无需恢复寄存器 R0~R3 的内容;
- 在函数中,通过寄存器 R4~R11 来保存局部变量;
- 寄存器 R12 用作函数间 scratch 寄存器;
scratch 寄存器是一个临时性的寄存器,通常用于存储临时数据或中间结果。它通常不用于存储重要的数据或程序状态,而是用于临时存储一些需要在短时间内使用的数据。scratch 寄存器在计算机体系结构中起到了临时存储数据的作用,有助于提高程序的执行效率和速度。在一些处理器架构中,scratch 寄存器也可能被用于传递参数或保存临时变量。
- 寄存器 R13 用作栈指针,记作 SP,在进入函数时的值和退出函数时的值必须相等;
- 寄存器 R14 用作链接寄存器,记作 LR,它用于保存函数的返回地址,如果在函数中保存了返回地址,则 R14 可用作其它的用途;
- 寄存器 R15 是程序计数器,记作 PC,它不能用作其他用途。
汇编程序如何向 C 程序的函数传递参数#
- 当参数小于等下 4 个时,使用寄存器 R0~R3 来进行参数传递。
- 当参数大于 4 个时,前四个参数按照上面方法传递,剩余参数传送到栈中,入栈的顺序与参数顺序相反,即最后一个参数先入栈
C 程序如何返回结果给汇编程序#
- 结果为一个 32 位的整数时,通过寄存器 R0 返回
- 结果为一个 64 位整数时,通过 R0 和 R1 返回,依此类推.
- 结果为一个浮点数时,通过浮点运算部件的寄存器 f0,d0 或 s0 返回
- 结果为一个复合的浮点数时,通过寄存器 f0-fN 或者 d0~dN 返回
- 对于位数更多的结果,通过调用内存来传递
C 函数为何要用栈#
- 保存现场/上下文(CPU 运行时寄存器的值)
- 传递参数(当函数被调用并且参数大于 4 个时,(不包括第 4 个参数)第 4 个参数后面的参数就保存在栈中。)