Linux驱动-内核自旋锁spinlock的实现
2024年7月 · 预计阅读时间: 3 分钟
自旋锁的定义#
自己在原地打转,等待资源可用。
SMP系统:原地打转的是CPU 1,之后CPU 2会解锁,CPU1就会获得资源了;
UP系统:自旋锁的“自旋”功能就去掉了:只剩下禁止抢占、禁止中断,即我先禁止别的线程来打断我(preempt_disable),我慢慢享用临界资源,用完再使能系统抢占(preempt_enable),这样别人就可以来抢资源了。
理解自旋锁最简单的方法就是把它当作一个变量,该变量把一个临界区标记为“我正在使用,请稍等”,或者“我当前不在运行,可以使用”。
需要回答两个问题:
1.一开始,怎么争抢资源?不能2个程序都抢到。
使用原子变量就可以实现。
2.某个程序已经获得资源,怎么防止别人来同时使用这个资源?
这是使用spinlock时要注意的地方,对应会有不同的衍生函数(_bh/_irq/_irqsave/_restore)
实现原理的“一图胜千言”:
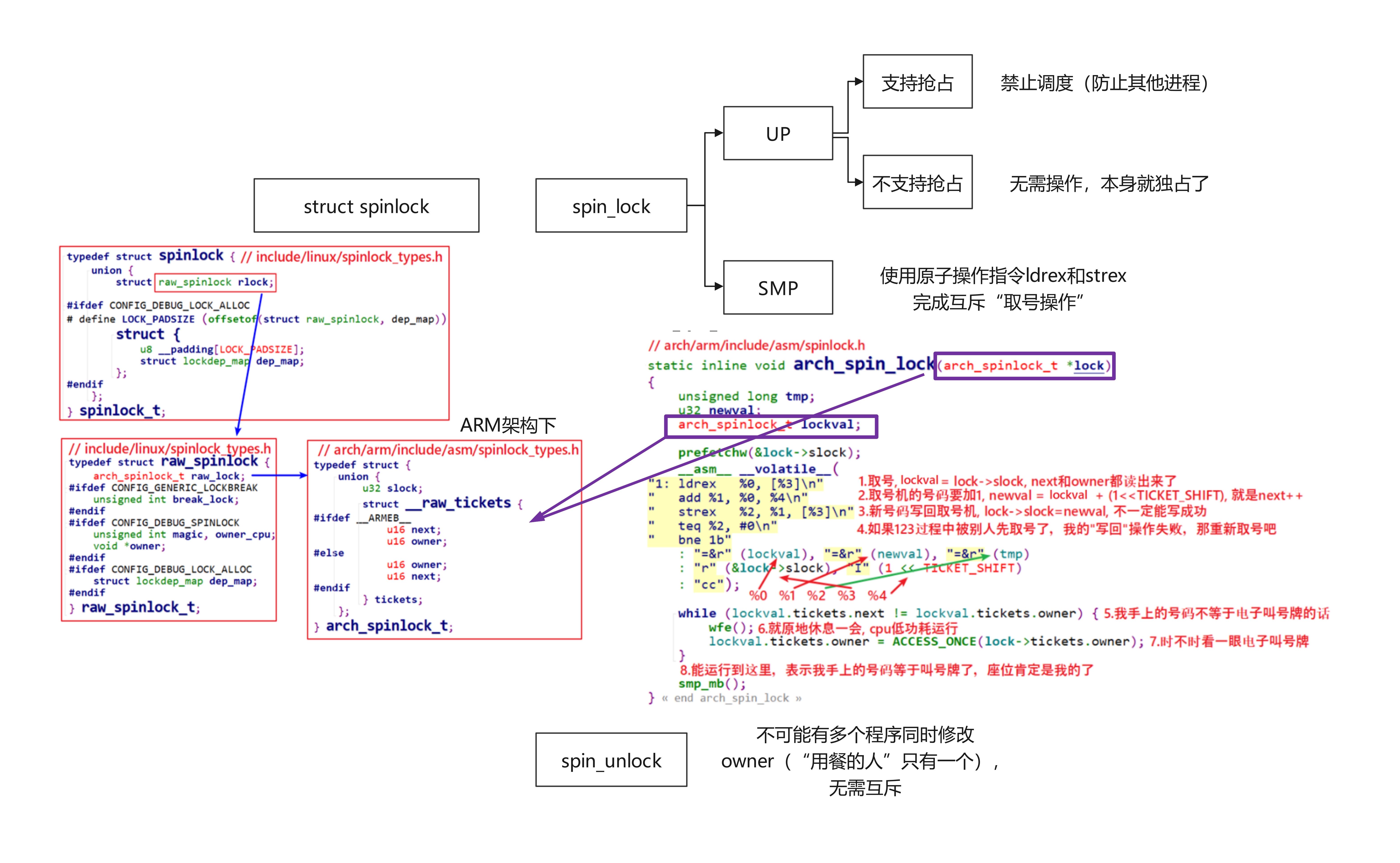
自旋锁的内核结构体#
spinlock对应的结构体如下:kernel/include/linux/spinlock_types.h
kernel/arch/arm/include/asm/spinlock_types.h
上述__raw_tickets结构体中有owner、next两个成员,这是在SMP系统中实现spinlock的关键。
下面会分为UP和SMP系统来介绍内核的自旋锁实现,即spin_lock和spin_unlock
spinlock在UP系统中的实现#
对于单CPU系统,没有“其他CPU”;如果内核不支持preempt,当前在内核态执行的线程也不可能被其他线程抢占,也就“没有其他进程/线程”。
所以
- 对于不支持preempt的单CPU系统,spin_lock是空函数,不需要做其他事情;
- 对于支持preempt的单CPU系统内核,即当前线程正在执行内核态函数时,它是有可能被别的线程抢占的,这时spin_lock的实现就是调用“preempt_disable()”。
1.spin_lock函数实现#
include/linux/spinlock.h
接着调用的是UP相关的api函数
include/linux/spinlock_api_up.h
在这里调用了禁止抢占preempt_disable
然后去获得锁:
__acquire(lock):
include/linux/compiler.h
从上述调用过程中可以展开为
在 UP 系统中 spin_lock()就退化为 preempt_disable(),如果用的内核不支持 preempt,那么 spin_lock()什么事都不用做。
2.spin_lock_irq函数实现#
include/linux/spinlock.h
include/linux/spinlock_api_up.h
对于 spin_lock_irq(),在 UP 系统中就退化为 local_irq_disable()和 preempt_disable(),假设程序 A 要访问临界资源,可能会有中断也来访问临界资源,可能会有程序 B 也来访问临界资源,那么使用 spin_lock_irq()来保护临界资源:先禁止中断防止中断来抢,再禁止 preempt 防止其他进程来抢。
3.spin_lock_bh#
对于 spin_lock_bh(),在 UP 系统中就退化为禁止软件中断和 preempt_disable()
disable both preemption (CONFIG_PREEMPT_COUNT) and softirqs,禁止调度和软件中断
4.spin_lock_irqsave#
对于 spin_lock_irqsave,它跟 spin_lock_irq 类似,只不过它是先保存中断状态再禁止中断
spinlock在SMP系统中的实现#
要让多CPU中只能有一个获得临界资源,使用原子变量就可以实现。
但是还要保证公平,先到先得。比如有CPU0、CPU1、CPU2都调用spin_lock想获得临界资源,谁先申请谁先获得。
在SMP系统中,维护自旋锁的原理类似于餐厅叫号:

餐厅里只有一个座位,去吃饭的人都得先取号、等叫号。注意,有2个动作:顾客从取号机取号,电子叫号牌叫号。
- 一开始取号机待取号码为0
- 顾客A从取号机得到号码0,电子叫号牌显示0,顾客A上座; 取号机显示下一个待取号码为1。
- 顾客B从取号机得到号码1,电子叫号牌还显示为0,顾客B等待; 取号机显示下一个待取号码为2。
- 顾客C从取号机得到号码2,电子叫号牌还显示为0,顾客C等待; 取号机显示下一个待取号码为3。
- 顾客A吃完离座,电子叫号牌显示为1,顾客B的号码等于1,他上座;
- 顾客B吃完离座,电子叫号牌显示为2,顾客C的号码等于2,他上座;
在这个例子中有2个号码:取号机显示的“下一个号码”,顾客取号后它会自动加1;电子叫号牌显示“当前号码”,顾客离座后它会自动加1。某个客户手上拿到的号码等于电子叫号牌的号码时,该客户上座
在这个过程中,即使顾客B、C同时到店,只要保证他们从取号机上得到的号码不同,他们就不会打架。
所以,关键点在于:取号机的号码发放,必须互斥,保证客户的号码互不相同。而电子叫号牌上号码的变动不需要保护,只有顾客离开后它才会变化,没人争抢它。
在ARMv6及以上的ARM架构中,支持SMP系统。
spinlock结构体一开始介绍过。owner就相当于电子叫号牌,现在谁在吃饭。next就当于于取号机,下一个号码是什么。每一个CPU从取号机上取到的号码保存在spin_lock函数中的局部变量里。
spin_lock调用过程如下:
include/linux/spinlock.h
kernel/locking/spinlock.c
include/linux/spinlock_api_smp.h
include/linux/spinlock.h
下面是架构相关的操作:

spin_unlock#
释放的时候不会有多个程序,所以不需要考虑互斥了