Linux驱动-同步互斥与原子变量
2024年7月 · 预计阅读时间: 3 分钟
同步与互斥失败的例子#
三个失败的同步互斥例子:
1.在 C 语言里面通过一个全局变量标志位判断,但是可能有多个进程读取这个变量,如果在没有修改变量前就切换了,那么多个进程都会任务自己拿到了这个标志
2.使用flag--来改变标志位,这样虽然把标志位的读取和改变结合到了一个 C 语言语句,但是在 CPU 执行时仍是分为“读取、修改、写入”三个步骤,依旧可能会产生切换导致多个进程获得标志
3.关中断方式:在单 CPU 系统上可以实现同步与互斥
但是,注意需要考虑多 CPU 的情况,对于 SMP 系统,你只能关闭当前 CPU 核的中断,别的 CPU 核还可以运行程序,它们也可以来执行这个函数.
注意:SMP 就是 Symmetric Multi-Processors,对称多处理器;UP 即 Uni-Processor,系统只有一个单核 CPU。
原子操作的实现原理与使用方法#
原子变量的操作函数:kernel\arch\arm\include\asm\atomic.h
原子变量类型#
如下,实际上就是一个结构体(内核文件kernel/include/linux/types.h)
原子变量内核操作函数#
| 函数名 | 作用 |
|---|---|
| atomic_read(v) | 读出原子变量的值,即v->counter |
| atomic_set(v,i) | 设置原子变量的值,即v->counter = i |
| atomic_inc(v) | v->counter++ |
| atomic_dec(v) | v->counter-- |
| atomic_add(i,v) | v->counter += i |
| atomic_sub(i,v) | v->counter -= i |
| atomic_inc_and_test(v) | 先加1,再判断新值是否等于0;等于0的话,返回值为1 |
| atomic_dec_and_test(v) | 先减1,再判断新值是否等于0;等于0的话,返回值为1 |
原子操作的定义#
atomic_read,atomic_set这些操作都只需要一条汇编指令,所以它们本身就是不可打断的。
例如:#define atomic_read(v) READ_ONCE((v)->counter)
问题在于atomic_inc这类操作,要读出、修改、写回。以atomic_inc为例,在atomic.h文件中,如下定义:
atomic_add又是怎样实现的呢?用下面这个宏:
宏定义:
以ATOMIC_OPS(add, +=, add)为例展开
在ARMv6及以上的原子加法使用内联汇编调用一些特殊的指令独占修改与写入ldrex/strex:

ldrex、strex指令,ex表示exclude,意为独占地。这2条指令要配合使用,如下:
- 读出:
ldrex r0, [r1]- 读取r1所指内存的数据,存入r0;并且标记r1所指内存为“独占访问”。
- 如果有其他程序再次执行“ldrex r0, [r1]”,一样会成功,一样会标记r1所指内存为“独占访问”。
- 修改r0的值
- 写入:
strex r2, r0, [r1]- 如果r1的“独占访问”标记还存在,则把r0的新值写入r1所指内存,并且清除“独占访问”的标记,把r2设为0表示成功。
- 如果r1的“独占访问”标记不存在了(有别的进程先清除了),就不会更新内存,并且把r2设为1表示失败。
在ARMv6及以上的架构中,原子操作不再需要关闭中断,关中断的花销太大了。并且关中断并不适合SMP多CPU系统,你关了CPU0的中断,CPU1也可能会来执行些操作啊。
在ARMv6及以上的架构中,原子操作的执行过程是可以被打断的,但是它的效果符合“原子”的定义:一个完整的“读、修改、写入”原子的,不会被别的程序打断。它的思路很简单:如果被别的程序打断了,那就重来,最后总会成功的。
原子变量的使用示例#
atomic_dec_and_test,这是一个原子操作,在ARMv6以下的CPU架构中,这个函数是在关中断的情况下执行的,它确实是“原子的”,执行过程不被打断。
但是在ARMv6及以上的CPU架构中,这个函数其实是可以被打断的,但是它实现了原子操作的效果,如下图所示:
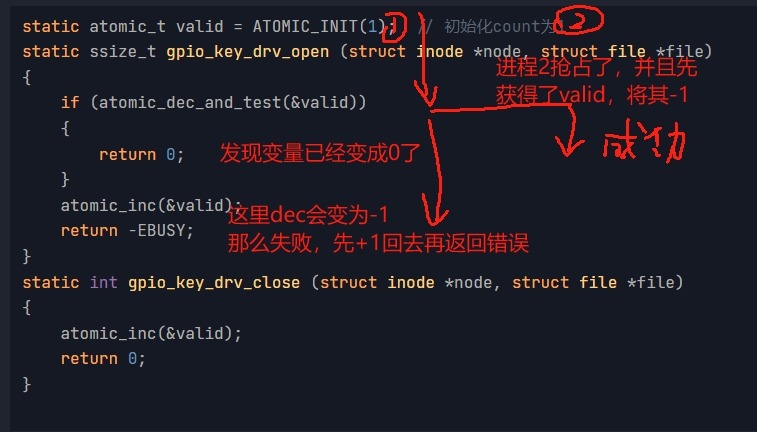
原子位#
原子位的操作函数在kernel\arch\arm\include\asm\bitops.h中,下表中p是一个unsigned long指针。
| 函数名 | 作用 |
|---|---|
| set_bit(nr,p) | 设置(*p)的bit nr为1 |
| clear_bit(nr,p) | 清除(*p)的bit nr为0 |
| change_bit(nr,p) | 改变(*p)的bit nr,从1变为0,或是从0变为1 |
| test_and_set_bit(nr,p) | 设置(*p)的bit nr为1,返回该位的老值 |
| test_and_clear_bit(nr,p) | 清除(*p)的bit nr为0,返回该位的老值 |
| test_and_change_bit(nr,p) | 改变(*p)的bit nr,从1变为0,或是从0变为1;返回该位的老值 |
在ARMv6以下的架构里,不支持SMP系统,原子位的操作函数也是简单粗暴:关中断。例如
在ARMv6及以上的架构中,不需要关中断,有ldrex、strex等指令,这些指令的作用在前面介绍过。还是以set_bit函数为例,代码如下:
